諸々を音声通知する
集中したいけどついついSlackを見ちゃったり、スケジュールやメールを見るのにアプリを切り替えたり、Notificationに目が行ったり…というコンテキストスイッチを極力省くため、これらを全部音声で通知する仕組みを作って運用し始めてみた。
Voiceroid
せっかく喋らせるんだし耳障りの良い声がいいなーってことでVoiceroidを導入した。選んだのはVoiceroid+ EX 結月ゆかり。
とはいえ開発機はmacで、VoiceroidはWindowsでしか動かないので、VPSのWindows Serverを借りてそこにインストールして使っている。
もちろんWeb APIなどは用意されていないので、HTTPSのサーバを立てて、VoiceroidアプリをWin32 APIを使って操作して音声ファイルを動的に生成、wav -> mp3へffmpegで変換してストリーム配信する仕組みを作った。
VPSは一番安そうで日本語OSになっているConoha for Windows Serverの2GBプランにした。ライセンス料が含まれるんだろうけど、Linuxより圧倒的に高い…。
なお、Voiceroidのライセンス認証はRDPからだと通らないようで、VNCで接続できるものでないといけない。なのでAWS Lightsailも検討したけど諦めた。
アーキテクチャ
以下のようなイメージ。クライアントとサーバの通信は全てGoで実装している。
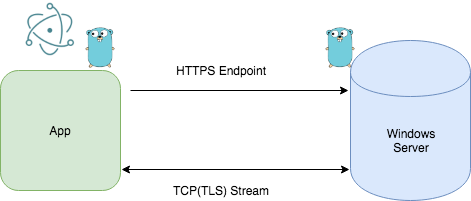
ボイスデータのリクエストはHTTPだけど、MP3の再生はサーバに繋ぎっぱなしのTCPストリーム経由でデバイスに繋いでいる。HTTPのレスポンスをそのまま再生してもいいけど、サーバ側からのボイスのPushも流せるようにTCPをつなぎっぱなしにする実装にした。定期的にping/pongを交換して接続を維持する仕様。
GoでのMP3デコーダ、再生周りはとても良いライブラリがある:
hajimehoshi/go-mp3 - An MP3 decoder in pure Go hajimehoshi/oto - ♪ A low-level library to play sound on multiple platforms ♪
ストリームインターフェースになっているのはとてもありがたい。
通知側、つまり開発機側macのインターフェースはElectronで作り、内部でGoのバイナリを動かしている。全部nodeで書いても良かったけど、初期実装をGoでやっていたのでElectronはUI周りのみとした。 Electron、TypeSciptサポートがちゃんとされててすごく書きやすくなってて良い。UIはSemantic UI Reactを使った。
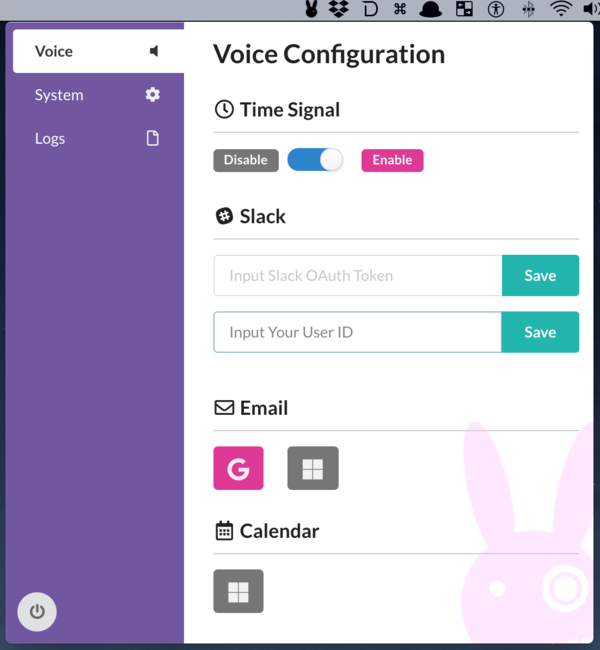 設定UI
設定UI
UIの通り、以下のような機能を載せている:
- 時報
- Slackの任意のチャンネル監視
- Gmailの新着メール通知
- Outlookの新着メール・イベント予定通知
設定ファイルの保存は Electron-Storeを使っていて、Goのクライアント起動時に設定ファイルへのパスを渡しつつファイル監視、変更があったらクライアントをリロードする、という実装になっている。
時報
なくてもいいけど、起動中にずっとしゃべらないのもなーってことで1時間毎に喋ってくれる。かわいい。
Slackの任意のチャンネル監視
Bot appを作ってWorkspaceにインストールし、そのトークンを入れておくと、inviteしたチャンネルへの新規投稿を喋ってくれる。 監視はSlack RTMを使っていてほぼリアルタイム。アプリ側から投稿することはないので無制限に監視できて、ユーザIDを入れると自身の投稿は省き、メンションもお知らせしてくれる。
Gmailの新着メール通知
OAuth2 + Gmail APIで実装している。これは golang.org/x/oauth2 が優秀で、一度トークンを発行するとrefreshなども自動的にやってくれるのでとても便利。
Outlookの新着メール・イベント予定通知
OAuth2 + Microsoft Graph APIで実装している。業務ではOutlookなので実装したが、Microsoft Graph APIを使うのは初めてだったので多少手間取った。が、基本的に golang.org/x/oauth2が面倒を見てくれるので、あとはAPIリファレンスを見ながら実装した。イベントは20分前から5分刻みに通知してくれるので忘れない。と思う。
音声入力
こちらも喋って入力したかったので、GCPのSpeech To Textを使ってマイク入力をテキスト変換し、それを入力とする機能を実装した。…が、業務中に「メール!」とか声を発するのは憚られるのでもっぱら通知のみにしている。
Speech To TextはどうしてもGCPと通信が発生するので発声からテキストを得るまで若干のタイムラグがあって、なんとかローカルでできないかとJuliusを試してみたが、精度は全くだめだった…
やけにCPUも回ったりしていたので開発に支障がでそうな感じだった。今後に期待だろうか。
パフォーマンス
HTTPリクエスト受信 -> Win32 APIでVoiceroid操作 -> ffmpegでwavからmp3に変換 -> ストリームに配信 というフローで、変換するテキストの量にもよるけど1リクエストに大体1-3秒くらいかかる。
また、一度に処理できるVoiceroidは当然一つなので、複数の音声リクエストがあった場合は待ちが発生する。これは逆に都合が良くて、1つのTCPストリームに順に流して行けばよいので、複数のリクエストはchannelで直列化している。もちろん他のVoiceroidを起動すればその限りではないけど…。
とはいえ、そこまでリアルタイム性を求めている訳ではないので良しとした。
まとめ
GoのアプリをWindows上で動かすのはなにげに初めてだったけど、何の問題もなく動作した。Windows操作には lxn/win というパッケージを使った。
lxn/win - A Windows API wrapper package for the Go Programming Language
DLLの処理をうまくラップしてくれてて、各APIの定数も一通り定義しれくれているので使いやすい。ただ、なぜか GetWindowTextW が実装されてなかったりで、不足しているAPIは syscall でなんとかする部分もあった。
また、Windows Serverのサービスにアプリを登録するために kardianos/service というパッケージがあって、これを使って登録したが、サービスの実行ユーザ指定がなぜかされなかったりで諦めて、普通にPowerShellからサーバを起動している。これは自分がWindowsに詳しくないのがいけないので、このあたりはもう少し調査したい。
kardianos/service - Run go programs as a service on major platforms.
とりあえずテキストを投げれば喋ってくれるインターフェースができたので、色々な通知系を音声に移行してみようと思っている。特定の入力でググったり何らかのAPIを叩いて結果を喋ったりとか。
一点、音声データの生成は自動化しているので、細かいフレーズや抑揚は付けられない。が、間違った読み上げをする単語(特に技術系のもの)は都度辞書に登録する作業があるが、これはこれで育てている感があって楽しい。
現場からは以上です。