以前のエントリでServerlessはまだ使うの怖いと言っておきながらの手のひら返し感ありますが、Serverless Architectureを実戦投入して1ヶ月くらい経ったので書きます。
作ったものはユーザアクセス収集基盤で、単一のAPIエンドポイントを用意して、そこにトラッキングのデータが投げられるのをバンバンTreasure Data(以下、TD)に流していく簡単なやつです。
もしもうまくいかなくても、それなりにスケールできるように作ったGolangのAPサーバもあったので、いざという時はそっちに切り替えようということで保険もあったので導入しました。 あとついでにServerless Frameworkが1.0@betaになっていたので先取りで使ってみようという意図も。
インフラエンジニアがいなくてもスケールする仕組み(楽したい)
インフラを専門に管理するエンジニアがいないけど、面倒を見る手間を省きたい。自分も専門ではないし、また今後導入対象が増えたときにも自動でスケールたい。ということで、フルマネージドなサービスで構築しようと決めました。
API Gateway + Lambdaの構成です。Serverless Frameworkで手軽に管理できて、なおかつそれぞれがリソースに対してオートスケールするので楽チン。月間で1,000万以上のアクセスが想定されてましたが、全く問題ありませんでした。
構成は大体こんなイメージです:
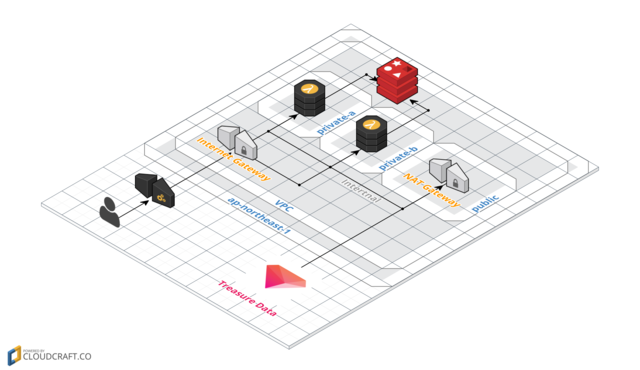
API GatewayのリクエストをLambdaに流して、認証とパラメータ整形をした上でTDのAPIをコールします。裏側のRedisはアカウント情報とTDのDatabaseを関連付けたシンプルなデータのみを保持。
こういう設計ではFluentdかembulkを使うのが定石かもですが、これらを動かすためにEC2を立てるのはServerless Architectureじゃないよなーってことで今回は直接TDにデータを流しています。
実際に稼働させて1ヶ月経ちますが、約100,000req/hでもエラーは一日数件程度で(その原因はRedisのコネクションタイムアウト)、それ以外に遅延も全くないのでまぁ安定していると言っていいかと思います。
RedisがSPOFになってしまったのは反省ですが、これもまたインスタンスのスペックを上げるなりしてしまえば解決する問題かなと思ってます。また、今後の導入対象の増加とリクエスト増大に対応するため、すぐにTDに投げるのではなく、一旦Kinesis Streamに溜めてからWorkerで処理する実装もしてあります。今は使ってませんが。
以前はLambdaからKinesis Streamのデータを取ってくるのにはLATESTかHORIZONしか指定できなかった記憶なんですが、今触ってみたらTRIM HORIZONになってて、前回処理からの差分だけをイベント検知できるようになってました。これ超便利なのでは。
他、ハマったポイントなど。
LambdaをVPC内で稼働させるときはprivate subnetでないといけない
LambdaのVPC内での稼働がサポートされたのですが、稼働するsubnetは2つ指定が必須、かつprivateでないといけないようでした。 で、privateなsubnetで稼働させると、ネットワークが外に出ていかない。つまり、外部APIがコールできないんですよね。なので、構成図のようにpublicなsubnetにNAT Gatewayを立てて、そこを経由して外に出ていけるように構築しないといけなかったです。
VPC内でLambdaを稼働させる際のハマりポイントだと思うので、参考になれば。
意外と手動設定しないといけない部分は多かった
後述する Serverless Frameworkが大体のことはやってくれますが、当然ですがVPCの構築は自分でやんないといけないです。
他にも実行Roleの追加AttachやKinesis Streamの設定など、楽とはいえちょいちょい手動設定ポイントがあります。 それでもEC2でなんやかんやするよりはコンソールで完結するので楽なのに変わりないですが。
API GatewayのSSL設定めんどくさい問題
API Gatewayを独自ドメイン+SSLで稼働させているのですが、このSSLはIAMと連動しておらず、証明書情報をテキストエリアに貼り付けて設定するという…。なんとも言えない感じでした。
手で作るのは結構大変ですが、Serverless Frameworkがその辺をよしなにやってくれたので手間が大幅に省けました。 あとAPIをコールするJavaScriptのSDKも作ったんですが、そちらもCloudFrontのCDN配信です。こちらもフルマネージド。
この構成で月間大体10,000,000アクセスがキャッシュなしで捌けて$200くらい(ちゃんと計算してない)。安いと思います。
Serverless Framework
少し前から追いかけてて、それはもうひどいくらい設計がぐるぐる変わってまだ時期じゃないなーって思ってましたが、メジャーバージョンになるってことで、semverで言うならようやっと落ち着いたかなってことで導入を決めました。
1.0.0になるまで、プロジェクト構成がpackageだったり、functionsだったりでなんじゃこれって思ってたんですが、1.0.0では結局handler+設定ファイルというシンプルな構成に落ち着いたようです。
AWS上のサービス構築はCloudFormationで雛形を作り、プロジェクトをzipでアーカイブしてS3にアップロードしてLambdaにインポート、API Gatewayの構築という風に進んでいきます。
これ書いてる内に、masterブランチは1.0.0RC2になってました。ですが、普通にnpmでインストールすると0.5.2が入るので、バージョン指定でインストールする必要があります:
$ npm install serverless@1.0.0-rc.2node.jsのプロジェクトを作成:
$ sls create -t aws-nodejsこれで雛形が生成されます。以前のverではGCPの設定があったんですが、なくなってました。正式版ではサポートされるのかな?当面はAWSで使えればいいけど。
設定ファイル(serverless.yml)はこんな感じ:
# Welcome to Serverless!
#
# This file is the main config file for your service.
# It's very minimal at this point and uses default values.
# You can always add more config options for more control.
# We've included some commented out config examples here.
# Just uncomment any of them to get that config option.
#
# For full config optionsundefined check the docs:
# v1.docs.serverless.com
#
# Happy Coding!
service: [app-name] # NOTE: update this with your service name
provider:
name: aws
runtime: nodejs4.3
vpc:
securityGroupIds:
- [securitygroup-id]
subnetIds:
- [subnet-id1]
- [subnetid-2]
# you can overwrite defaults here
defaults:
stage: dev
region: ap-northeast-1
memory: 128
timeout: 30
# you can add packaging information here
package:
#include:
# - include-me.js
functions:
track:
handler: handler.index
events:
- http:
path: foo
method: get
# you can add CloudFormation resource templates here
#resources:
# Resources:
# newResource:
# Type: AWS::S3::Bucket
# Properties:
# BucketName: newBucketproviderセクションにランタイムやVPCの設定を記述し、functionsセクションにLambdaのハンドラとHTTPのエンドポイントの指定を行うのが基本かな。eventsにはスケジューラの指定とかもできます。
他にもResourcesにKinesisの指定もできたりするけど、手元の環境ではうまくいかず、デプロイ後に手動で設定していた。プラグインも特に作ってない。
Serverless Frameworkを使って思った点をいくつか。
Stage指定を変更すると別APIになる
$ sls deploy -s stgとかやってstgというStage(ややこしい)にデプロイすると、一つのAPI内にstgというStageができるかと思いきや、別APIが新規作成された。ちょっと挙動おかしい気もするけど、環境が分けられる点ではまぁ同じなので良しとした。
ローカルで完結するの超便利
ローカルからslsコマンドで大体完結するのが便利。特に、
$ sls logs -f [function] -tとやるとCloudWatchのログをtailしながら流してくれるのが便利すぎる。
Role問題で色々躓く
上述の設定ではVPC内にLambaをデプロイして稼働させますが、この時RoleにAWSLambdaVPCAccessExecutionRoleが無いと駄目です。が、その辺のRole登録はやってくれないので、自分で付けないといけなかった。
さらに、プロジェクト毎にRoleが新規作成されるんですが、これに付与する必要があるため、一回デプロイ→失敗→でもRoleは作成されている→Roleに権限付与→成功 みたいな不毛なフローが発生する。設定に基いてRole追加はよしなにやってほしいけど、仕方ないのかなーとは思う。
エラーが不親切すぎてやばい
Role問題にも関連しますが、内部で順番にサービス構築をしていく中で、失敗するとエラーになったとき、エラー詳細がほとんど表示されません。SLS_DEBUG環境変数をつけてもJSのスタックトレースが出るだけで全くわからず、原因特定が非常に困難。
慣れてくるとステップで大体ここかなって検討がつくようになりますが、ここはもっと改善して欲しいところではあります。
とはいえ、一度デプロイ成功するスタックを作ってしまえば、運用はとても簡単です。ローカルでイベントエミュレートもできるので、ローカルでテストしてOKならデプロイするだけです。
ダウンタイムはありませんが、各種リソース(ネットワーク)の再構築が走るので、その間にレスポンス遅延は発生します。なのでデプロイしまくっても大丈夫、というわけではないですかね。
今(2016/09現在)ググって出るServerless Frameworkのエントリは殆どが過去のバージョンのものなので注意。全然プロジェクトツリーが違います。なので公式GithubのDocumentを見るのが良いです。
1.0.0の正式版になったら中のソースをちゃんと読み込もうと思います。あと、9/30 - 10/1 に serverlessconf やるらしいですよ。
まとめ
フルマネージドなサービスで構築するのがServerless Architectureということで、Serverless Frameworkを使わなくてもポチポチやっていけば構築できますが、やっぱり使ったほうが便利だと思います。
とはいえ、AWSとかのことを全く知らなくてもできるかというとそうでもなくて、意外とハマりポイントがあるので、ある程度知識のある状態で導入するのがオススメかと。
シンプルだけど大量のアクセスを捌くAPIエンドポイントを構築する際の選択肢としは大いにアリだと思いました。ですが、普通のWeb Appのスタックとしてはまだちょっと厳しいかな?って印象です。
現場からは以上です。
References:
Serverless Documentation (v1) New – Access Resources in a VPC from Your Lambda Functions Amazon API Gateway を独自ドメインで利用する